
Oracle Cloud Infrastructure (OCI) is used by many of our customers to run their Oracle E-Business Suite workload. Especially when not just running development and testing systems on OCI obviously this needs a solid concept for backing up (and restoring) the environment in the event of a disaster – be it user or system errors. Let’s take a closer look at the options available.
Basic concepts and terminology
RPO and RTO
The two most important notions when designing a backup strategy are definitely the Recovery Point Objective (RPO) and the Recovery Time Objective (RTO). RPO is the amount of data one is accepting to loose in case of a disaster. For example, an RPO of 30 minutes means that in any situation you never want to lose more than 30 minutes of transactions when a disaster happens. RTO is the time it takes to recover from a disaster and have an instance up and running again. The oracle documentation on the database – especially the “High availability overview” – provides more details on this:
OCI levels of isolation
There are three isolation levels associated with Oracle Cloud Infrastructure that help to protect against failures, see the OCI documentation on this:
- Region: A region is a highly isolated part of Oracle Cloud Infrastructure, which is located in a geographical area, e.g. EU-Frankfurt or US-WEST (Phoenix). Separating across regions provides protection even against e.g. large natural disasters.
- Availability Domains: Most regions are divided into 3 Availability Domains. These are isolated data centers and thus are very unlikely to fail simultaneously. Because availability domains do not share infrastructure such as power or cooling, or the internal availability domain network, a failure in one availability domain within a region is unlikely to impact the availability of other domains within the same region.
- Fault Domain: This is a partition within one data center. By putting compute instances in different Fault domains, the failure of a physical box in Fault Domain 1 does not impact a physical box (and its compute instances) in Fault Domain 2.
Block-, Object- and File Storage
Oracle Cloud Infrastructure offers 3 major types of Storage with different advantages and disadvantages. All 3 types are also relevant for backups:
- Block Storage is storage that is attached to a compute instance as either a boot or an additional volume. Usually the attachment happens through iSCSI. While performance is very high, Block Storage resides in just one Availability Domain (the one where the compute instance is running). Block Volumes can be conveniently backed up at specified times through backup policies, and these backups can also be put to the object storage across regions. All the data from E-Business Suite instances (Apps- and DB-Tier) are usually located on block volumes.
- Object Storage can be viewed as a “web service”, with which particularly large objects can be saved and called up. It is “per region” and highly durable by automatically storing several copies across multiple Availability Domains.
- File Storage provides a NFS mount point that can be attached to multiple compute instances, eventually also across availability domains (or even regions if they are connected). While the service is a “per AD” service, the File Storage can be in AD1, while a compute instance in AD2 for convenient access to the storage. The service provides snapshot functionalities and stores multiple (durable) copies of all data (within one AD).
Objectives for this discussion
For the further scope of this blog, I will describe strategies that will help to get an RPO and RTO of both approximately 30 minutes (for production systems). The strategy should be able to handle outages of one Availability Domain, but does not need to cover “regional-outages”.
I will handle three different scenarios in this blog post since different procedures are appropriate for them:
- Handling of Development instances
- Handling of Conference Room Pilot or other testing instances
- Handling of Production instances
Development Instances
Typically on development instances it is not necessary to have a “full blown” backup of the instance. In case of a disaster, one is usually able to just create a new development instance as a new copy of the production system. If all developers work according to “common best practices”, they have all their source code in one source code management system and can easily reinstall this source code onto the new development system.
In reality, however, this is not always the case. Especially with PL/SQL and APEX development, it is a widespread practice to develop directly in the database and only occasionally put the source code into a version control system – often only when moving from development to testing.
To cover this scenario, it is advisable to also carry out “some backups” of development systems. It is however usually enough to backup the following content:
- (Custom) Database objects such as packages, procedures or views: Those can be easily backed up using expdp with a “XX%”-Name-Filter that is run at e.g. 8 AM, Noon and 4 PM. The result can be backed up to a file storage in a different Availability Domain and restored from there after a new development instance has been created.
- APEX Applications can be backed up using sqlcl. This can again be run multiple times per day and the result can be written to a file storage location.
- XML Publisher Reports are stored in the xdo_lobs table. This table can be dumped regularly using expdp.
We put all the three exports into a shell script that cleans up old data after 4 weeks, providing a safety net for developers who do not immediately check-in their source code to GIT.
This means a RPO of 4 hours (for source code only) and an RTO of 2-12 hours (create a new P2T copy and restore the latest source code). The cost is minimal – storing appx. 1 GB in File Storage.
CRP and Testing instances
The above procedure allows you to sign all the .jar files of an E-Business Suite environment without copying the files to a different server. What I do not like so far thus is that I have to run that sign.sh shown above on/after every patch application. In an upcoming blog post, I will evaluate if there is a way to overwrite/overrule the built-in jarsigner command of adop/adadmin with the command shown above signing the code using Certum Cloud.
CRP or Testing instances can play a crucial role, especially when running a new E-Business Suite implementation project. It is often not so easy to just replace them with new copies of production, especially during the hot phases of e.g. a User Acceptance Test.
I have had good experiences using Block Volume Backups that were created either manually or at fixed times (often incrementally) by using custom or pre-built backup policies. Such backups can be easily captured from the Apps- and DB Block Volume as well as the Boot Volume. The backups are “consistent snapshots” of the underlying volume at the time they were taken. It is easy (within seconds) to create block volumes from the boot- and data-volumes and then start a new database and apps tier compute instance based on this backup. This can be done within a few minutes.
I usually attach a policy as follows:
- Run a full backup every Sunday morning at 2 AM. Keep this backup for 2 weeks.
- Run a daily incremental backup at 4 AM. Keep this backup for 5 days.
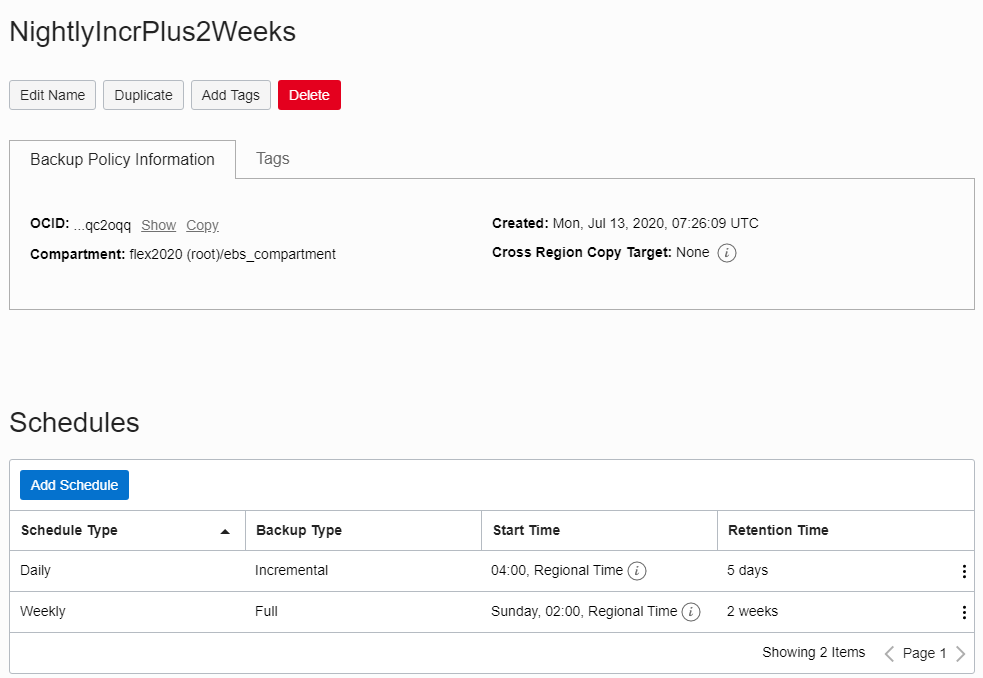
This means a RPO of up to one day and an RTO of appx. 30 minutes. The costs depend on the size of the instance, on a medium size instance it is appx. in the area of 25-50 $/Month.
Production
In production, it is often not acceptable to lose an entire day of work in case of a disaster. The traditional way to handle this is by using regular RMAN full/incremental backups in combination with a backup of the recent archivelogs. This can be used to reach an RPO of appx. 30 minutes quite easily. The drawback of this method is RTO: if the database is large, restoring the latest full backup followed by an incremental backup, followed by applying all the latest archive logs. On instances with many terabytes of data this may easily take a full day to restore and recover.
However, there is a convenient “turbo-mode” for this approach: Starting with the Oracle Database Release 12c recovery can be performed based on “3rd party storage snapshots“. This allows combining a snapshot approach as shown in the previous section with applying the archive logs only from the current day.
The main steps to set this up are:
- Setup a File Storage in a different Availability Domain and mount it to the Database Tier.
- Setup this mount point as a second / optional archive log destination.
- Make sure an archive log is created at least every 30 minutes by using the archive_lag_target parameter.
- Optionally: Define the above mount point as a secondary control file location.
This approach gives an RPO of 30 minutes with an RTO of 30 to 90 minutes (depending on the amount of archive logs to be applied). The costs are the costs of the 1day storage snapshot costs described previously plus File Storage for the Archive Logs of 1 day.
Apps Tier for Production
So far we have primarily covered the Database Tier of an E-Business Suite instance. For the Apps Tier, one of the following approaches could be used:
- Put the $INST_TOP onto a NFS share on File Storage or
- Implement a rsync backup of $INST_TOP on a block volume to a remote File Storage location or
- Make sure that no crucial data is on the Apps Tier: Often this data is only temporary and does not need to be backed up more than once a day.
Summary
As shown above Oracle Cloud Infrastructure provides powerful, easy to use and cost effective ways to cover all backup and recovery needs for E-Business Suite instances. Short RPO and RTO times can be achieved way easier than when using traditional On Premise Data Centers.